Substituição a quente num servidor dedicado em RAID por software
Substitua um disco com defeito num servidor dedicado em RAID por software sem interrupção graças ao procedimento de hot-swap
Sumário
Nos servidores Alta Gama compatíveis, é possível substituir um disco danificado a quente.
Descubra as principais etapas para substituir a quente um disco num servidor com RAID por software.
Requisitos
- Dispor de um servidor mHG, HG ou BHG.
- Possuir um RAID por software (com placa LSI).
- Dispor de um acesso SSH (Linux) ou RDP (Windows).
- Ter instalado o utilitário “sas2ircu”(utilize o motor de busca Broadcom para o encontrar).
Instruções
Em Linux
1 - Identificar o disco afetado
Neste manual partiremos do princípio de que o cliente recebeu um alerta para o disco /dev/sdb, indicando-lhe que está defeituoso e que precisa de ser substituído a quente. Adapte os comandos indicados neste manual à sua situação.
Comece por testar e verificar o serial number (número de série) do disco danificado.
root@ns3054662:/home# smartctl -a /dev/sdb
>>> smartctl 6.4 2014-10-07 r4002 [x86_64-linux-3.14.32-xxxx-grs-ipv6-64] (local build)
>>> Copyright (C) 2002-14, Bruce Allen, Christian Franke, www.smartmontools.org
>>> === START OF INFORMATION SECTION ===
>>> Vendor: HGST
>>> Product: HUS726040ALS210
>>> Revision: A907
>>> Compliance: SPC-4
>>> User Capacity: 4,000,787,030,016 bytes [4.00 TB]
>>> Logical block size: 512 bytes
>>> LB provisioning type: unreported, LBPME=0, LBPRZ=0
>>> Rotation Rate: 7200 rpm
>>> Form Factor: 3.5 inches
>>> Logical Unit id: 0x5000cca25d3155bc
>>> Serial number: K4GW439B
>>> Device type: disk
>>> Transport protocol: SAS (SPL-3)
>>> Local Time is: Mon Nov 21 14:23:43 2016 CET
>>> SMART support is: Available - device has SMART capability.
>>> SMART support is: Enabled
>>> Temperature Warning: Enabled
>>> === START OF READ SMART DATA SECTION ===
>>> SMART Health Status: OK
>>> Current Drive Temperature: 34 C
>>> Drive Trip Temperature: 85 C
>>> Manufactured in week 44 of year 2016
>>> Specified cycle count over device lifetime: 50000
>>> Accumulated start-stop cycles: 9
>>> Specified load-unload count over device lifetime: 600000
>>> Accumulated load-unload cycles: 14
>>> Elements in grown defect list: 0
>>> Vendor (Seagate) cache information
>>> Blocks sent to initiator = 2305525022720
>>> Error counter log:
>>> Errors Corrected by Total Correction Gigabytes Total
>>> ECC rereads/ errors algorithm processed uncorrected
>>> fast | delayed rewrites corrected invocations [10^9 bytes] errors
>>> read: 0 572 0 22548 77 4.725 5580
>>> write: 0 0 0 19548 196 17.344 2569
>>> Non-medium error count: 0
>>> SMART Self-test log
>>> Num Test Status segment LifeTime LBA_first_err [SK ASC ASQ]
>>> Description number (hours)
>>> # 1 Background short Completed - 6 - [- - -]
>>> # 2 Background short Completed - 4 - [- - -]
>>> # 3 Background short Completed - 4 - [- - -]
>>> # 4 Background short Completed - 4 - [- - -]
>>> # 5 Background short Completed - 1 - [- - -]
>>> Long (extended) Self Test duration: 34237 seconds [570.6 minutes]
Aqui, poderá notar que:
- o disco “SDB” está fora de serviço devido aos erros que não foram corrigidos (“uncorrected errors”);
- o seu número de série corresponde ao da alerta recebida (enviada do datacenter ou através de qualquer outra ferramenta de monitorização).
Para obter apenas o número de série:
root@ns3054662:/home# smartctl -a /dev/sdb | grep Serial
>>> Serial number: K4GW439B
2 - Obter a posição do disco
A seguir, deverá identificar a slot e o enclosure do disco afetado. Para isso, utilize a ferramenta “sas2ircu” previamente instalada no servidor.
Comece por verificar que os discos estão bem conectados através de uma placa LSI.
root@ns3054662:/home# lspci | grep -i LSI
>>> 81:00.0 Serial Attached SCSI controller: LSI Logic / Symbios Logic SAS2004 PCI-Express Fusion-MPT SAS-2 [Spitfire] (rev 03)
Se for o caso, identifique o ID dessa placa LSI.
root@ns3054662:/home# ./sas2ircu list
>>> LSI Corporation SAS2 IR Configuration Utility.
>>> Version 5.00.00.00 (2010.02.09)
>>> Copyright (c) 2009 LSI Corporation. All rights reserved.
>>> Adapter Vendor Device SubSys SubSys
>>> Index Type ID ID Pci Address Ven ID Dev ID
>>> ----- ------------ ------ ------ ----------------- ------ ------
>>> 0 SAS2004 1000h 70h 00h:81h:00h:00h 1000h 3010h
>>> SAS2IRCU: Utility Completed Successfully.
O index corresponde ao ID. Neste exemplo, o index (índice) e o ID da placa é 0.
Com esta informação poderá obter a slot e o enclosure do disco danificado através do seu número de série.
root@ns3054662:/home# ./sas2ircu 0 display | grep -B 7 -A 2 K4GW439B
>>> Device is a Hard disk
>>> Enclosure : 1
>>> Slot : 3
>>> State : Available (AVL)
>>> Manufacturer : HGST
>>> Model Number : HUS726040ALS210
>>> Firmware Revision : A907
>>> Serial No : K4GW439B
>>> Protocol : SAS
>>> Drive Type : SAS_HDD
Este comando permite consultar a informação do disco, cujo número de série é K4GW439B.
No nosso exemplo, obtivemos o enclosure (que aqui corresponde a 1) e a slot (neste caso, 3).
3 - Ligar o disco
Uma vez que tiver os dados indicados nos passos anteriores, ligue o led do disco que deve ser substituído com o comando ./sas2ircu 0 locate Enc:Slot on. Personalize-o para se adaptar à sua situação, conforme o exemplo abaixo:
root@ns3054662:/home# ./sas2ircu 0 locate 1:3 on
>>> LSI Corporation SAS2 IR Configuration Utility.
>>> Version 5.00.00.00 (2010.02.09)
>>> Copyright (c) 2009 LSI Corporation. All rights reserved.
>>> SAS2IRCU: LOCATE Command completed successfully.
>>> SAS2IRCU: Command LOCATE Completed Successfully.
>>> SAS2IRCU: Utility Completed Successfully.
Para que o disco pare de piscar, substitua “on” por “off” no comando.
4 - Retirar o disco danificado do RAID
Se ainda não o fez, ponha o disco danificado em faulty. A seguir, verifique o estado do RAID.
root@ns3054662:/home# cat /proc/mdstat
>>> Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4] [multipath] [faulty]
>>> md2 : active raid1 sda2[0] sdb2[1]
>>> 3885385728 blocks super 1.2 [2/2] [UU]
>>> bitmap: 0/29 pages [0KB], 65536KB chunk
>>> md1 : active raid1 sdb1[1] sda1[0]
>>> 20971456 blocks [2/2] [UU]
>>> unused devices: `<none>`
Neste exemplo, o disco danificado faz parte de md1 e md2 (sdb1 e sdb2). Por isso, vamos passar em faulty “sdb1” e “sdb2” de “md1” e “md2” respetivamente.
root@ns3054662:/home# mdadm --manage /dev/md1 --set-faulty /dev/sdb1
>>> mdadm: set /dev/sdb1 faulty in /dev/md1
root@ns3054662:/home# mdadm --manage /dev/md2 --set-faulty /dev/sdb2
>>> mdadm: set /dev/sdb2 faulty in /dev/md2
Um vez concluída esta operação, volte a verificar o estado do RAID.
root@ns3054662:/home# cat /proc/mdstat
>>> Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4] [multipath] [faulty]
>>> md2 : active raid1 sda2[0] sdb2[1](/pt/dedicated/hotswap-raid-software/F)
>>> 3885385728 blocks super 1.2 [2/1] [U_]
>>> bitmap: 0/29 pages [0KB], 65536KB chunk
>>> md1 : active raid1 sdb1[2](/pt/dedicated/hotswap-raid-software/F) sda1[0]
>>> 20971456 blocks [2/1] [U_]
>>> unused devices: `<none>`
Como podemos ver acima, “sdb1” e “sdb2” já estão em faulty (F). Já pode retirar o disco do RAID.
root@ns3054662:/home# mdadm --manage /dev/md1 --remove /dev/sdb1
>>> mdadm: hot removed /dev/sdb1 from /dev/md1
root@ns3054662:/home# mdadm --manage /dev/md2 --remove /dev/sdb2
>>> mdadm: hot removed /dev/sdb2 from /dev/md2
Finalmente, verifique que o disco já não está presente.
root@ns3054662:/home# cat /proc/mdstat
>>> Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4] [multipath] [faulty]
>>> md2 : active raid1 sda2[0]
>>> 3885385728 blocks super 1.2 [2/1] [U_]
>>> bitmap: 0/29 pages [0KB], 65536KB chunk
>>> md1 : active raid1 sda1[0]
>>> 20971456 blocks [2/1] [U_]
>>> unused devices: `<none>`
O disco danificado já pode ser substituído por um técnico do datacenter. Uma vez a operação efetuada, só terá de voltar a sincronizar o RAID. Para isso, consulte a seguinte documentação: RAID software.
Em Windows
1 - Identificar o disco
Neste manual partiremos do princípio de que o cliente recebeu um alerta para o disco /dev/sdb, indicando-lhe que está defeituoso e que precisa de ser substituído a quente. Adapte os comandos indicados neste manual à sua situação.
Info
É importante abrir o terminal de comandos enquanto administrador para evitar erros.
Comece por testar e verificar o serial number (número de série) do disco danificado. Na seguinte captura de ecrã, o armazenamento na realidade não está fora de serviço.
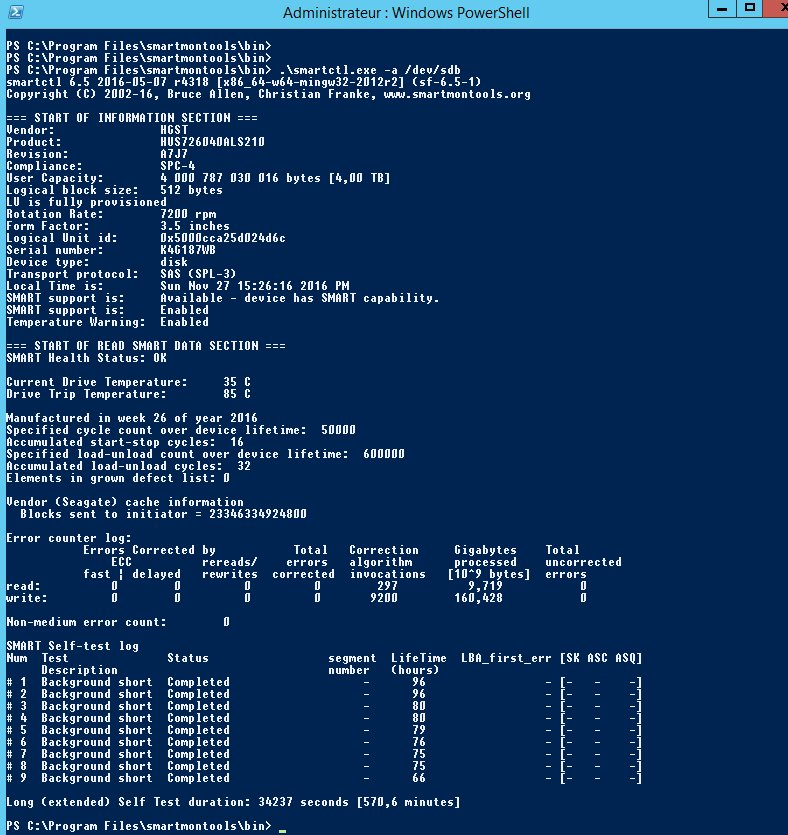
Aqui, poderá notar que:
- o disco “SDB” está fora de serviço devido aos erros que não foram corrigidos (“uncorrected errors”);
- o seu número de série corresponde ao da alerta recebida (enviada do datacenter ou através de qualquer outra ferramenta de monitorização).
2 - Obter a posição do disco
A seguir, deverá identificar a slot e o enclosure do disco afetado. Para isso, utilize a ferramenta “sas2ircu” previamente instalada no servidor.
Comece por determinar o ID desta placa LSI.
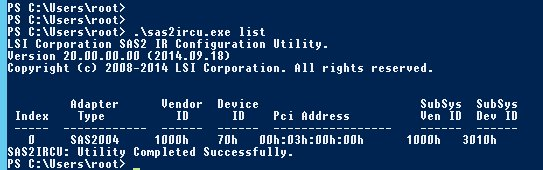
O index (índice) e o ID da placa é 0.
Com esta informação poderá obter a slot e o enclosure do disco danificado através do seu número de série.
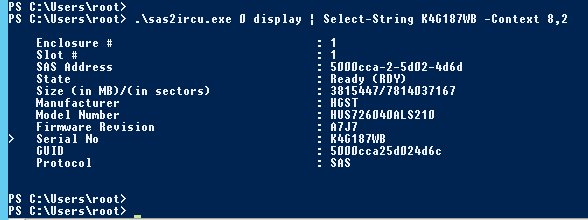
Este comando permite consultar a informação do disco, cujo número de série é K4G187WB.
No nosso exemplo, obtivemos o enclosure (que aqui corresponde a 1) e a slot (neste caso, 1).
3 - Ligar o disco
Uma vez que tiver os dados indicados nos passos anteriores, ligue o led do disco que deve ser substituído com o comando ./sas2ircu 0 locate Enc:Slot on. Personalize-o para se adaptar à sua situação, conforme o exemplo abaixo:
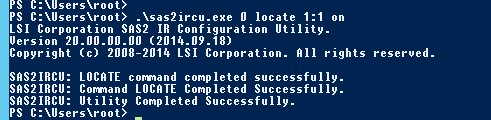
Para que o disco pare de piscar, substitua “on” por “off” no comando.
4 - Retirar o disco danificado do RAID
Esta operação pode ser realizada a partir da interface Gestão dos discos do servidor Windows.
O disco danificado já pode ser substituído por um técnico do datacenter. Uma vez a operação efetuada, só terá de voltar a sincronizar o RAID. Para isso, consulte a seguinte documentação: RAID software.
Quer saber mais?
RAID por software
OVHcloud API and Storage
Fale com nossa comunidade de utilizadores.